Intersection between Implicit Curves
Interscetion between two implicit curves
I worked with GeoGebra during summer 2015, and implemented some functionality including intersection of implicit curves. The experience were exciting, and I learnt significantly. Here I would like to share a some of them, hope it may help you. Anyway finding intersection between simple curves are far easy; however, when we have to implement functionality that work well with a wide range of implicit equations the task becomes partially intractable and needs sophisticated approach to deal with edge and corner cases. Particularly, in this post I would discuss two different method to find intersection between two implicit curves and . I would start with simple problem formulation, manual solution followed by two methods - Newton’s and Broyden’s method to find intersections.
Problem formulation
For two different implicit curves and find some points , where and , in such that and .
Example
Let and . From second equation we get . When we substitute this value in the first equation we get . Thus satisfies both equation. But, it is not always so simple. It is difficult to find the solution of and .
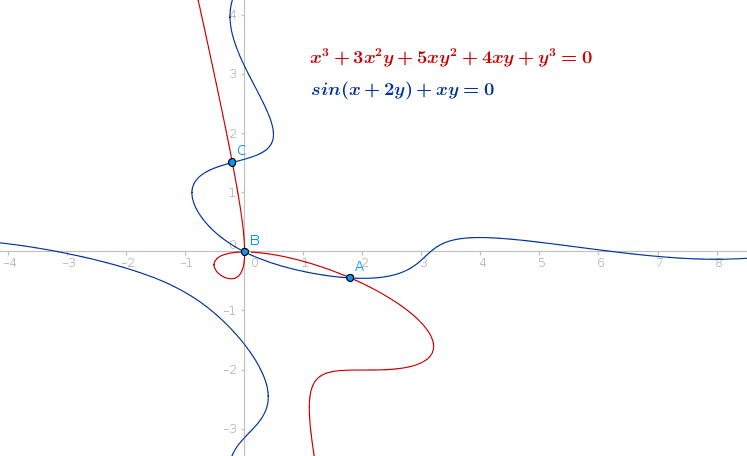 Figure 1: Intersection example (in GeoGebra Beta): This was a fun and relatively hard example with any root near zero converges slowly towards zero. Also notice that the red curve has a singular point at origin and there exists root at origin but the jacobian matrix at origin is singular which makes the problem difficult.
Figure 1: Intersection example (in GeoGebra Beta): This was a fun and relatively hard example with any root near zero converges slowly towards zero. Also notice that the red curve has a singular point at origin and there exists root at origin but the jacobian matrix at origin is singular which makes the problem difficult.
Newton’s Method
Newton’s method is an iterative method which is used to find roots of function . In this method we begin with some intial guess and iteratively update initial guess with a better approximation using following expression until desired accuracy is achieved
The same idea can be extended to find intersection between two implicit curves. we know that
We begin with some intial guess , and try to move small step in the best direction that is the move for which .
To avoid clutter let’s define
, , , , , , and the same for g(x). We can write
where , and
Since is a 2x2 square matrix it is simple to find its inverse.
Now the expression becomes
Where
The idea can be extended to equation even in higher dimension.
Browse code here
// java code for the intersection of implicit curves
public class Solver {
public static interface FunctionXY {
public double evaluate(double x, double y);
public double derivativeX(double x, double y);
public double derivativeY(double x, double y);
}
public static boolean isZero(double v, double eps) {
return (v > -eps) && (v < eps);
}
public static void add(List<double[]> sols, double x, double y) {
for(int i = 0; i < sols.size(); i++) {
double[] v = sols.get(i);
if(isZero(x - v[0], 1e-6) && isZero(y - v[1], 1e-6)) {
return;
}
}
sols.add(new double[]{x, y});
}
public static List<double[]> solve(FunctionXY f, FunctionXY g,
double[] bounds, double eps) {
double[][] samples = rootSamples(f, g, bounds, 10, 10);
List<double[]> sols = new ArrayList<>();
double x1, y1, x2, y2, er, er1, fv, gv, fv1, gv1;
double jfx, jfy, jgx, jgy, det, alpha, dx, dy;
int MAX_ITR = 8;
boolean success;
for(int i = 0; i < samples.length; i++) {
x1 = samples[i][0];
y1 = samples[i][1];
fv = f.evaluate(x1, y1);
gv = g.evaluate(x1, y1);
er = Math.abs(fv) + Math.abs(gv);
for(int j = 0; j < MAX_ITR && !isZero(er, eps); j++) {
jfx = f.derivativeX(x1, y1);
jfy = f.derivativeY(x1, y1);
jgx = g.derivativeX(x1, y1);
jgy = g.derivativeY(x1, y1);
det = jfx * jgy - jfy * jgx;
if(isZero(det, 1e-8)) {
break;
}
dx = (jgy * fv - jfy * gv) / det;
dy = (jfx * fv - jgx * gv) / det;
alpha = 1.0;
success = false;
// We can use line search that satisfies
// Wolfe condition, but for now keep it
// simple
do {
x2 = x1 - dx;
y2 = y1 - dy;
fv1 = f.evaluate(x2, y2);
gv1 = f.evaluate(x2, y2);
er1 = Math.abs(fv1) + Math.abs(gv1);
if(er1 < er) {
success = true;
// variable exchange
break;
}
alpha *= 0.8;
} while(alpha >= 0.01);
if(!success) break;
}
if(isZero(er, eps)) {
add(sols, x1, y1);
}
}
return sols;
}
/**
* divide the entire space in 10x10 grid and evaluate
* f and g at each vertex return mid point of consecutive
* vertices for which both functions change their sign.
*/
public double[][] rootSamples(FunctionXY f, FunctionXY g, double[] bounds,
int sampleXSize, int sampleYSize) {
return null;
}
}Damping
You maight have noticed that in each iteration algorithm starts with full step size and reduces it until the error become smaller than the previous error or the move becomes too small. It is necessary because sometimes the step size that is chosen by the algorithm is too large that leads to divergence. To avoid it we introduce a damping factor
where
Do be a good choice of damping factor? Let’s take an example of and . When we start from point the step size without damping is . If we take or we reach at the root in a single step. Therefore which is a good value : , or . In our example seemingly is a better choice than . However look at the figure-2, when we start at point the full step length leads to point far from the solution, at (chosen heuristically) we get point which is close to the solution. For an arbitray unknown equation there is no known good way to select the exact value of . We assume that the function is continuous in the neiborhood, and try to move in the direction that may have solution. A long jump may violet our initial assumption. Furhtermore when we bound the range of we can apply search heuristic to find better value.
Read here about damping related tricks and optimization
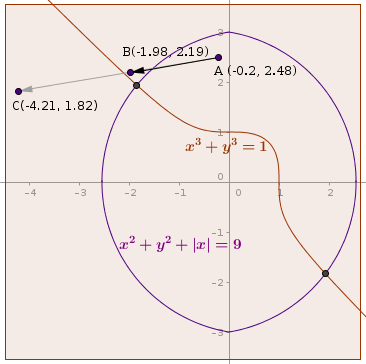 Figure 2: Line search for good value of
Figure 2: Line search for good value of
Selecting Damping Factor
There are several approaches to select damping factor we can use quadratic interpolation, line search, binary search, quadratic decay rate, (will post more about it soon)
Convergence of Newton’s Method
Let’s begin with an intuitive discussion. Suppose both functions, and are linear bivariate function. That is, and . Since the higher order error term is zero, Newton’s method should produce the correct answer in a single iteration as long as jacobian matrix is invertible. Following derivation shows that in fact it does give the solution in a single step. Notice that the end result is nothing but the solution that we get by directly applying Cramer’s rule.
If the inital guess is then
We have seen that in case of linear implicit equation Newton’s method converges in one iteration. In general case the behaviour depends upon the error term . That is one of the reasons we use damping factor - we never want divergence of error. So when we choose the gradient direction to move in, we also ensure that the error doesn’t exceed the previous error. If it does we reduce (damp) the direction by . You might be thinking about how we can choose a good direction, how much we should damp, and how we can ensure that damping would not help to reach at solution. As in following equation
You may try to visualize the graph. (Edit: No real value of and satisfies any of the above equation, though at the left side is very close to zero.)
Limitations
- For implicit curve both functions should be smooth in and differentiable
- It is computationally expensive to evaluate derivative at each step
- Near singular jacobian matrix sometimes leads to divergence
- If starting point is not close to the solution, the algorithm may not converge quickly or even may diverge
Broyden’s Method
Broyden’s method, originally described by CG Broyden, is a quasi-Newton method for root finding. In contrast to Newton’s method, in which we have to calculate jacobian matrix in each iteration, we calculate jacobian only in the first iteration and we do rank one update in other iterations. Broyden’s method converges to solution in iterations for linear system, however it may even fail to converge for non-linear system of equation.
We start with the idea of secant method for one variable. The finite difference approximation of is given by
When we substitute this value to Newton iteration, we get
To develop intuition about how we can update from let’s start with following expression all in
Here it seems absurd to expand middle term to get right hand side expression. But we notice that in the middle term we are directly calculating but in right hand side we are updating previous derivative to get new one.
A failed attempt
To extend the idea let us define following notations in
The secant equation using jacobian matrix can be written as
To reduce clutters we define , and
Now using new notations we can write
We can see that,
Therefore,
Alternatively we can use Sherman-Morrison formula to find directly inverse of Jacobian matrix:
where
Though the final expression for the rank-one jacobian update is a valid expression the steps that lead to it is not valid. Notice the is a singular matrix therefore it is not invertible. Suppose for a moment that it is invertible, to reach at conclusion we have added and substracted previous jacobian . Why do we have chosen the previous jacobian? We may have selected a null matrix or nothing at all. What the last expression is actually doing?
Let’s start from scratch, in Newton’s Method the next good approximation is given by following expression
and to prevent divergence we use , where can take any value. Now each function can be regarded as a function of single variable namely and we would like to find an optimum value of it. Since partial derivative is assumed to exist we can take partial derivative of each function with respect to and applying chain rule we can write -
Hence if an accurate estimate of availabe we can approximate jacobian matrix . For now assuming only function of Taylor series expansion about ignoring higher order terms can be written as
The last equation relates to four already known quantities to fifth to which an approximation is available and to which a new estimation is sought. In the class of method explained by Broyden is chosen in such a way as to satisfy the equation
The above expression relates the change in function vector to change of in the direction of , there is no information available about the behavior of function in other directions. Therefore it is not possible to obtain fresh rate of change in these directions. According to the first method suggested by Broyden chosen so that the change is predicted by in a direction orthogonal to is the same as would be predicted by . Symbolically,
Above two eqaution is sufficient to define uniquely and its unique value is given by
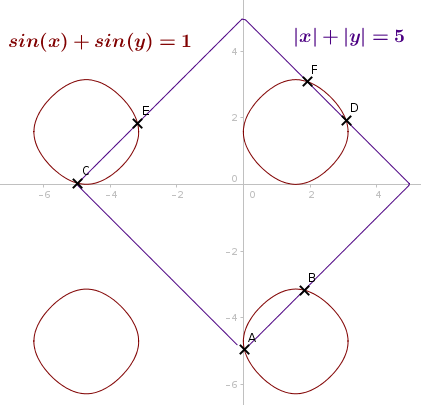 Figure 3: Intersection with absolute value function(Using Broyden Method)
Figure 3: Intersection with absolute value function(Using Broyden Method)
Other Applications
Geometry
Root finding method can be used to find the tangents of a curve from a given point. For example - let the curve be , point is a point on the curve and we want to draw some tangent lines from point . When we draw a line , slope of must be equal to the slope of curve at . In mathematical terms we can write
The right hand side represents the slope of the line passing through two distinct points and . The term in the left is derivative of curve which can be calculated as
After some manipulation we will get another implicit curve equation as
Now we can solve and to get some points on the curve where the slope of the curve is same as that of the line passing through .
Local minimum of function (Minimising cost function : Machine Learning)
This is a widely studied problem because we often need to find minimum or maximum value of a function in engineering, mathematics, statistics, machine learning and operation research. Here we only discuss minimization because maximizing is equivalent to minimizing . In this problem we are interested in finding a stationary point which statisfies where is the value of function in the close neighborhood of . At the stationary point
This partial derivatives will give us equations in . We can solve these equations using the technique discussed above, or we can use some advanced optimization techniques such as BFGS, L-BFGS, or conjugate gradient.
Happy Reading!
Reference
[1] - Broyden, C. G. (October 1965), “A Class of Methods for Solving Nonlinear Simultaneous Equations”, Mathematics of Computation (American Mathematical Society) 19 (92): 577–593. doi:https://dx.doi.org/10.2307%2F2003941
[2] - Jorge Nocedal, Stephen J. Wright. “Numerical Optimization”